k-Means Clustering
k-Means Clustering is a machine-learning technique that is used to group similar data points. k-Means Clustering can be used to create management zones by grouping similar areas of a field based on their underlying characteristics. When performed correctly, the produced zones should group areas with similar landscape positions, soil composition, yield potential, and management requirements.
To use the k-Means Clustering tool in PCT, navigate to the Zone/Locate tool and follow the steps below.
Steps:
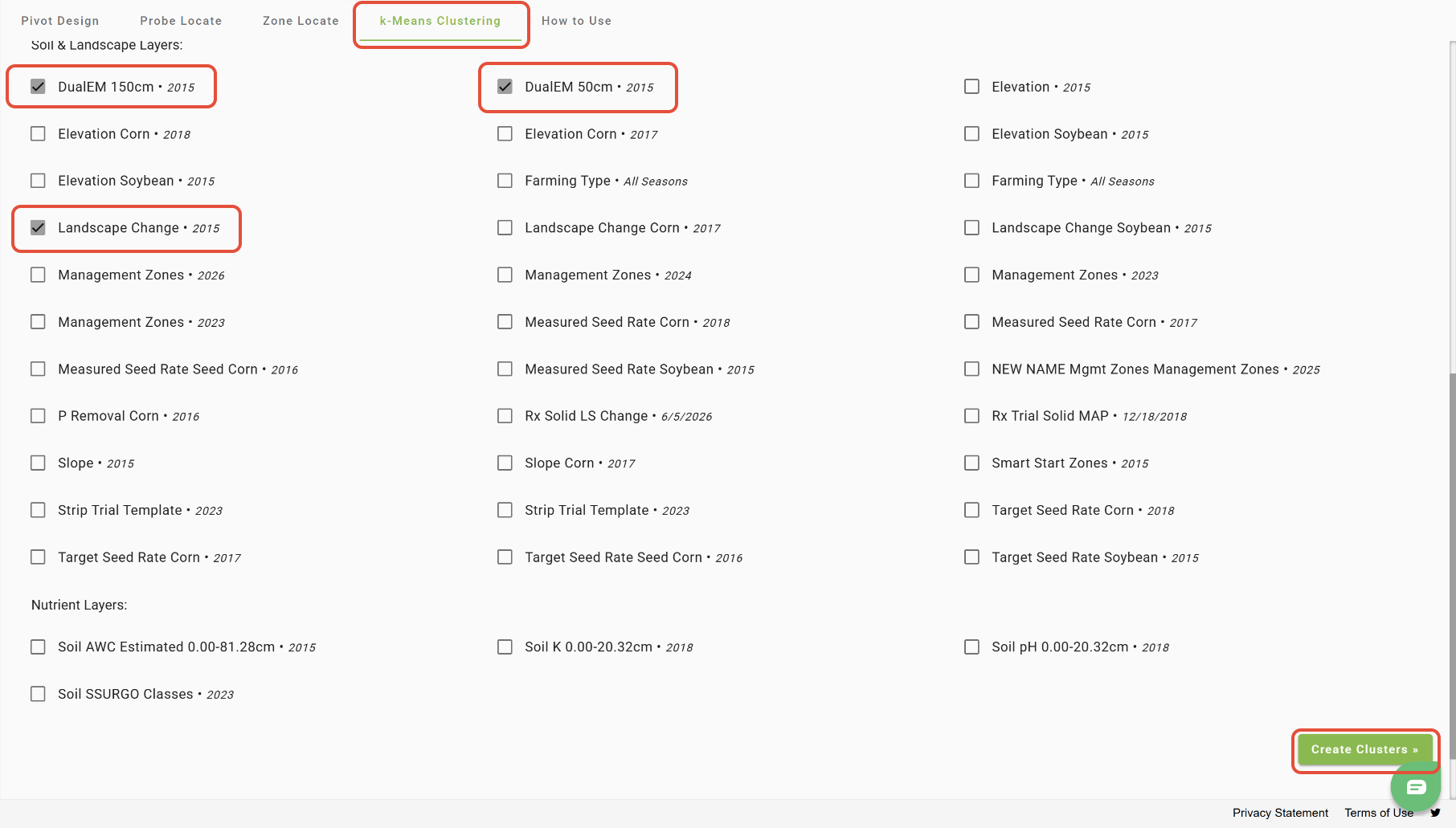
In the Zone/Locate tool with a Field selected, open the 'k-Means Clustering' tab, select the desired layers, and click 'Create Clusters'.
Once the cluster has been run, you can change the order and smoothing of the maps. 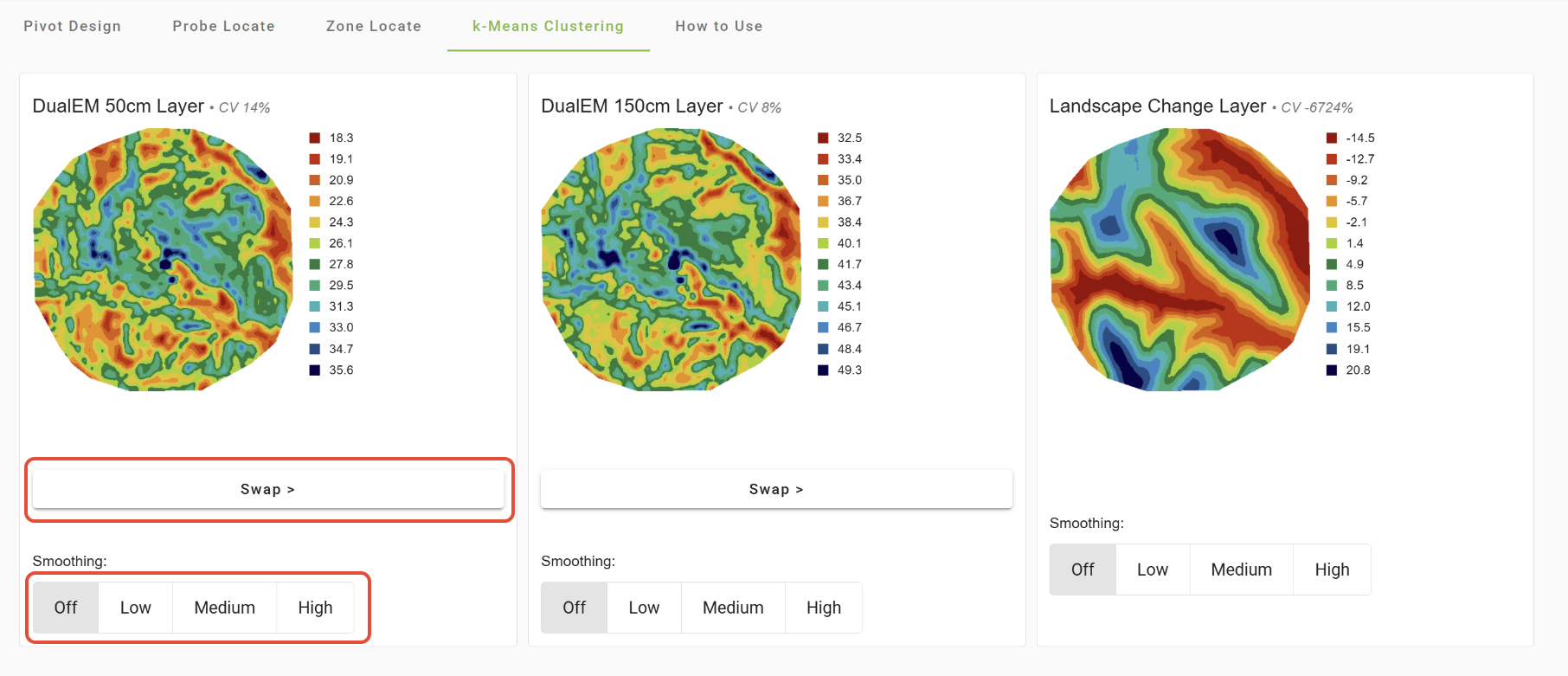
The number of clusters may be selected manually or statistically. The ideal number of clusters for each field will differ depending on the within-field variability and intended management practices. The 'Show ideal cluster count' button runs all scenarios from 2 to 10 clusters and displays the Within-Cluster Sum of Squares (WCSS) plot. You also have the option to alter the consolidation of small zones within the map.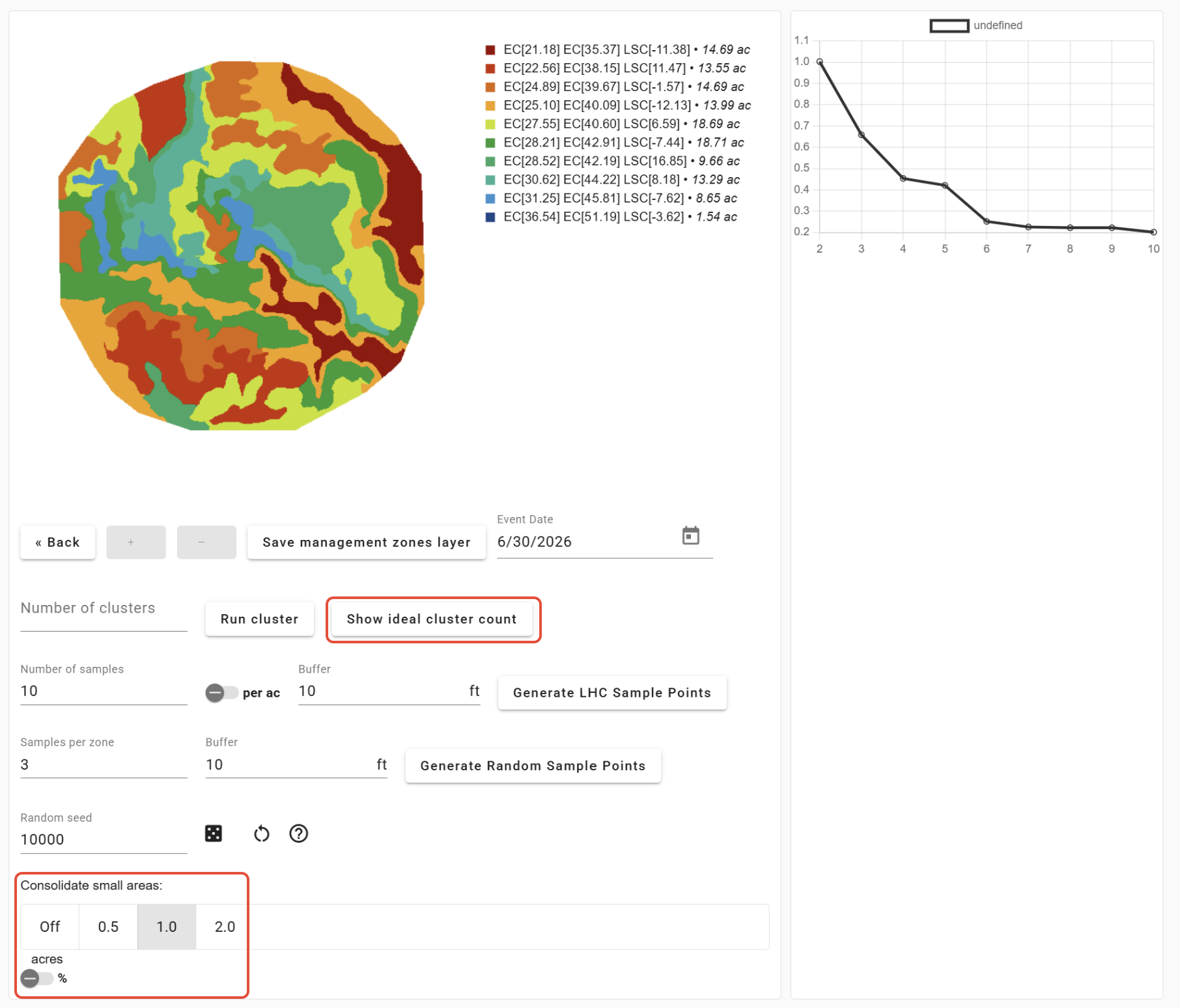
When using the 'Show ideal cluster count' option, remember that as the number of clusters increases, the WCSS tends to decrease. The ideal number of clusters is the "elbow" point of the plot, where the rate of decrease in WCSS significantly slows down. This point represents a good balance between minimizing within-cluster variability and avoiding excessive fragmentation into small clusters. However, the elbow method is only a guide; it is not definitive. It is important to strike a balance between finding a reasonable number of clusters and ensuring they have practical and interpretable implications. 
Once the ideal number of clusters has been determined using the elbow method, enter the number and click 'Run cluster'. When finished, click 'Save management zone layer'. 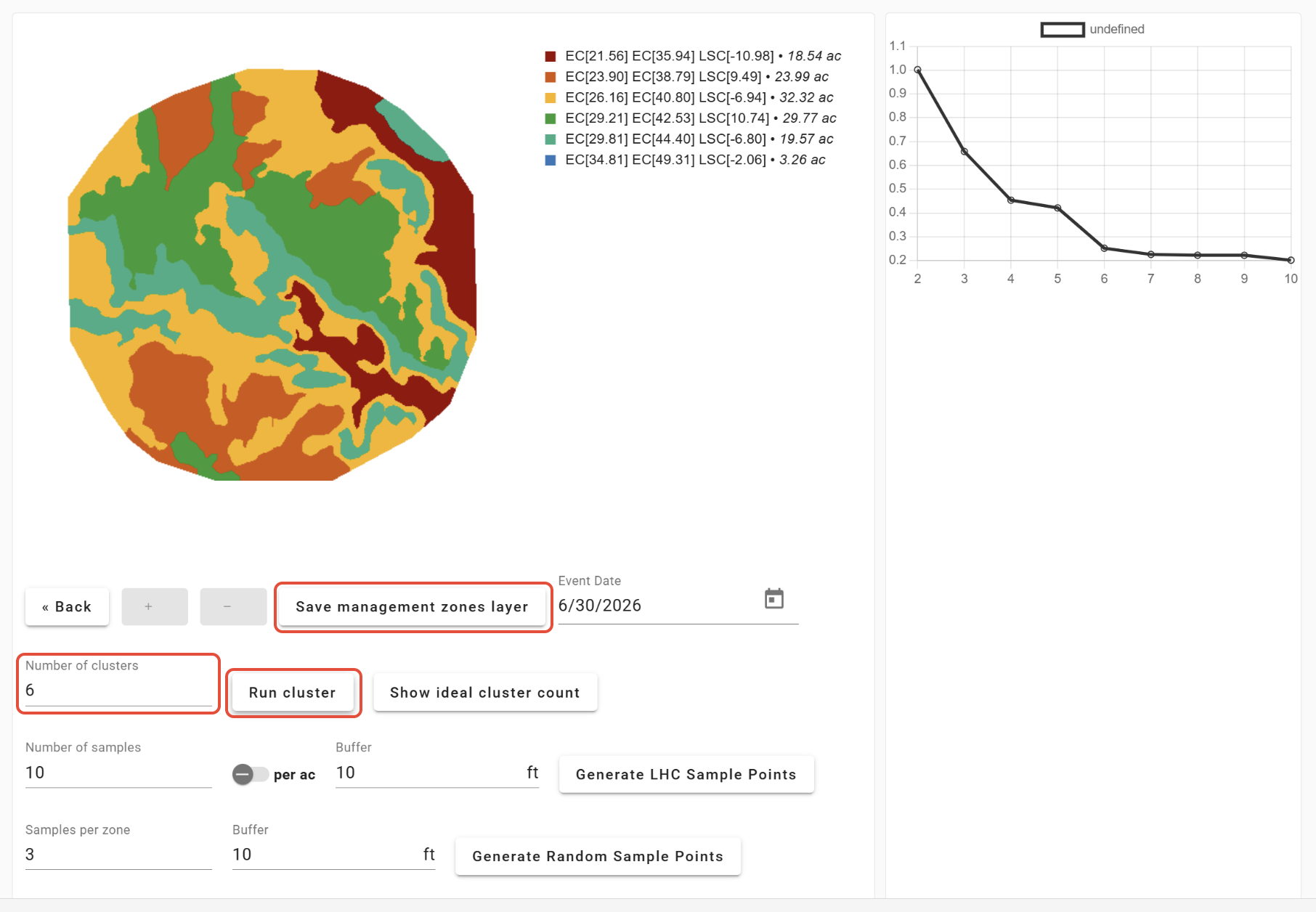
Sample Locations
As with other zoning tools in PCT Agcloud, you have the option to place or generate sample points within the k-Means Clustering tool.
To place individual points on the map, simply click on the zoned map.
Soil sampling plans can also be generated using either stratified random sampling with the 'Generate Random Sample Points' button or conditioned Latin hypercube sampling with the 'Generate LHC Sample Points' button. For both options, you may select a buffer width to prevent sampling on the edges of fields or boundaries between zones.
The 'Generate Random Sample Points' option only utilizes the developed management zone layer and allocates the given number of samples randomly within each zone.
The 'Generate LHC Sample Points' option considers data in the input layers to optimize where the sampling sites are located. The samples are positioned so that they capture the maximum amount of variability in the input layers from the given number of sampling locations. This minimizes correlation between sampling points and increases the overall efficiency of the sampling plan. LHC will not necessarily put an equal number of samples in each zone.
Once the points have been plotted, click the 'Save points' button at the bottom of the page. The points in the example below were created using the LHC option.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article